
Für viele kann die Vorstellung eine SEO-Analyse zu machen überwältigend sein. Aber es gibt Tools, wie beispielsweise den Screaming Frog, welche diese Aufgabe für Neulinge und für Profis gleichermaßen erleichtert. Dieser Guide gibt Dir Einblicke in die Einstellungen und Möglichkeiten des Screaming Frog und erleichtert die Arbeit bei SEO-Audits, Keyword Recherche, Wettbewerbsanalyse, Linkmanagement und noch vielem mehr.
So Crawls Du jede Website
Im nächsten Abschnitt zeigen wir Dir, wie Du mit bestimmtes Einstellungen im Streaming Frog größere, ältere Webseiten und über einen Proxy Server crawlen kannst.
Die gesamte Website crawlen
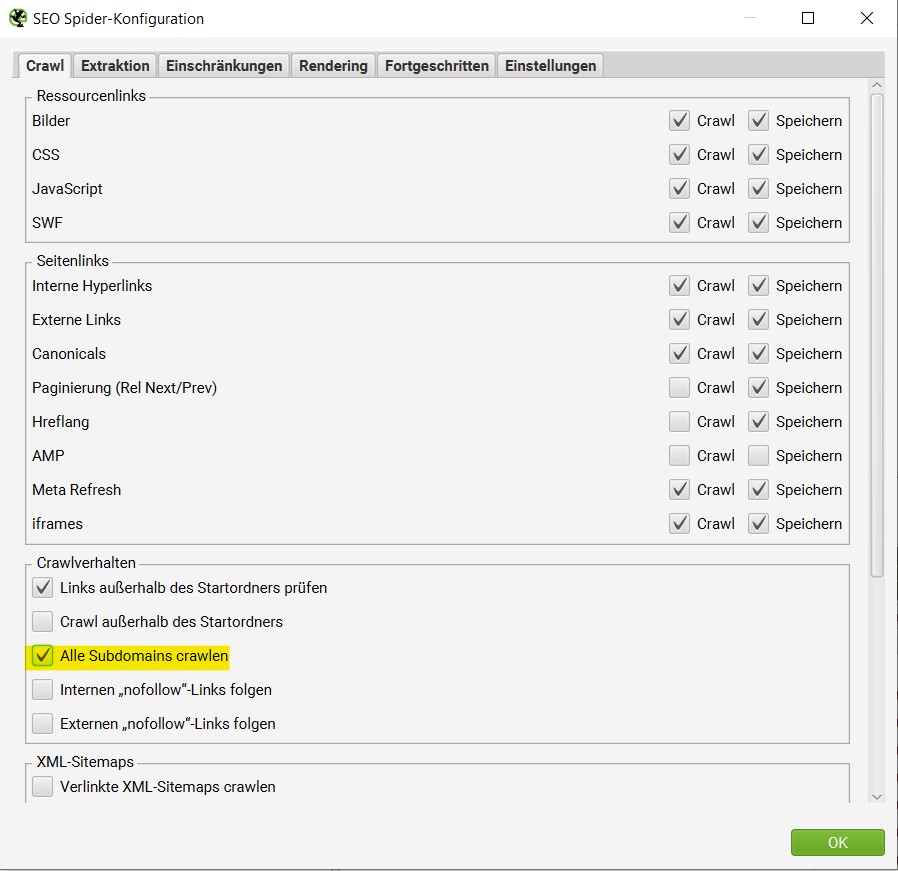
Im Normalfall durchsucht Screaming Frog nur die eingegebene Subdomain. Jede zusätzliche Subdomain wird als externer Link angezeigt. Mit zusätzlicher Einstellung unter „Konfiguration“ im Menüpunkt „SEO Spider“ kannst Du weitere Subdomains crawlen lassen. Wird in diesem Untermenü der Punkt „alle Subdomains crawlen“ ausgewählt, ist sichergestellt, dass der Crawler bei der nächsten Suche alle Subdomains durchsucht, die auf der angegebenen Seite zu finden sind.
Zusammenfassung: Konfiguration → SEO Spider → Alle Subdomains crawlen
Eine große Website crawlen
Screaming Frog wurde nicht dafür entwickelt, abertausende URLs zu durchsuchen. Aber es gibt trotzdem ein paar Tricks, mit denen es sich verhindern lässt, dass das Tool abstürzt, wenn es größere Webseiten crawlen soll. Als Erstes ist es möglich, die Speicherzuweisung des Spiders zu erhöhen. Diese findest Du unter “Konfiguration” – System” – “Speicherzuweisung”. Ein weiterer Punkt ist nur das Durchsuchen von bestimmten Teilen einer Webseite (Kapitel: Bestimmte URLs beim Crawl einbeziehen und ausschließen).
Reichen diese Einstellungen immer noch nicht aus, kann über bestimmte Einstellungen verhindert werden, dass alle Bilder, JavaScript- und CSS-Dateien, PDFs sowie Flash gecrawlt werden, auf die der Spider bei der Suche trifft. Im Fall einer großen Website sollen jetzt ausschließlich Objekte vom Typ HTML durchsucht und alle Unterseiten aufgelistet werden.
Über “Konfiguration” – “SEO Spider” müssen Punkte “Bilder“, „CSS“, „JavaScript“ und “SWF“ abgewählt werden. Zudem muss die Checkbox “Crawl außerhalb des Startordners” gewählt sein, damit nicht nur das Startverzeichnis beachtet wird.
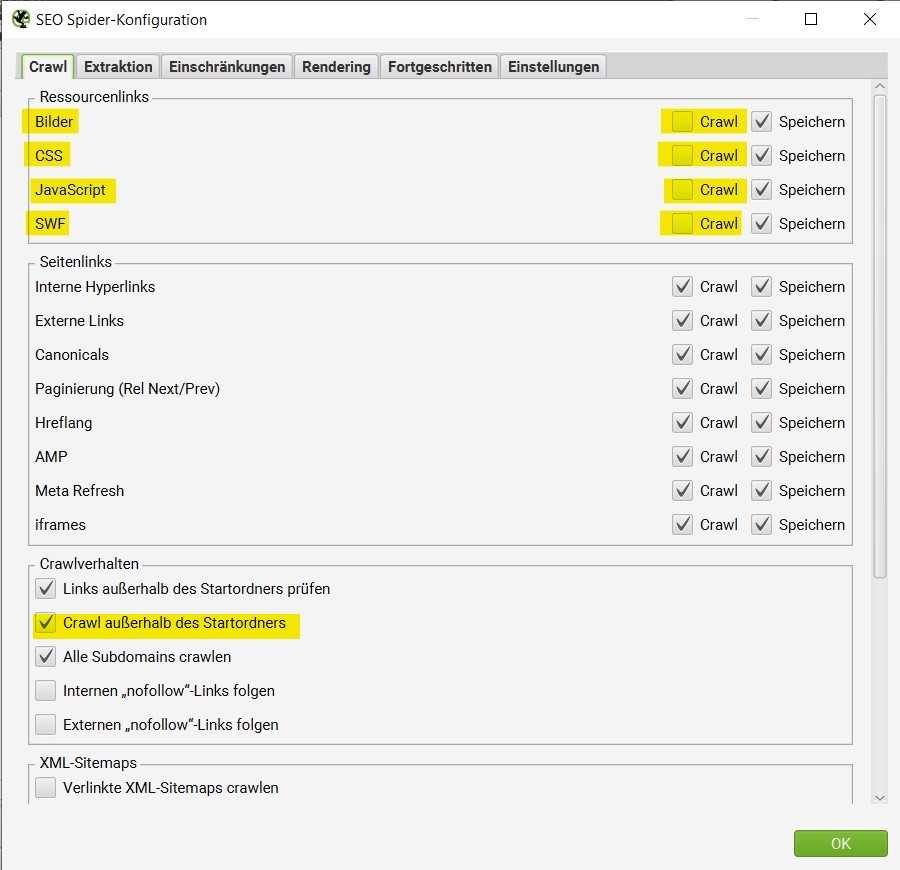
Wird mit diesen Einstellungen der Crawl gestartet, so wird eine Liste mit allen Unterseiten der Internetseite zurückgegeben. Im Reiter “Intern” können nun die HTML-Dateien analysiert werden.
Über einen Proxy-Server crawlen
Wenn ein Proxy-Server zum Crawlen verwendet werden soll, kannst Du im Einstellungsmenü (Konfiguration) den Unterpunkt „System → Proxy“ auswählen. An dieser Stelle können die Adresse und der Port des Proxys eingegeben werden. Veränderst Du diese Einstellungen, ist es wichtig Screaming Frog neu zu starten, damit diese Änderung angewendet wird.
Über verschiedene “Benutzer-Agenten” crawlen
Soll das Crawlen mit einem anderen “User-Agenten” durchgeführt werden, gibt es hierfür ebenfalls eine Möglichkeit. Unter Konfiguration → Benutzer-Agent können andere “User-Agents” ausgewählt oder eingetragen werden.
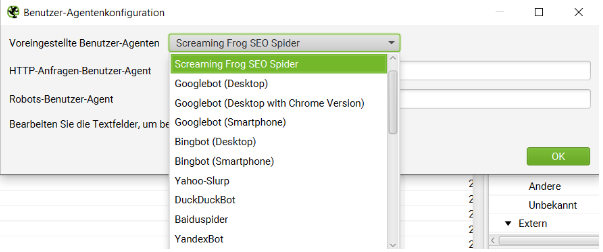
Zusammenfassung: Konfiguration → Benutzer-Agent
Ältere Websites oder Websites mit Crawldelay crawlen
In seltenen Fällen sind manche ältere Server nicht in der Lage, die Anzahl von Standardanfragen pro Sekunde zu verarbeiten. In diesem Fall bietet Screaming Frog die Möglichkeit, die Geschwindigkeit des Crawlers zu ändern. Dafür gibt es im Menüpunkt “Konfiguration“ den Unterpunkt “Geschwindigkeit.“ Hier kann die maximale Anzahl an Threads eingestellt werden, die gleichzeitig ausgeführt werden sollen. Zusätzlich ist es möglich, die maximale Anzahl der pro Sekunde angeforderten URLs anzugeben.
Zusammenfassung: Konfiguration → Geschwindigkeit
Den Spider außerhalb eines bestimmten Ordners crawlen lassen
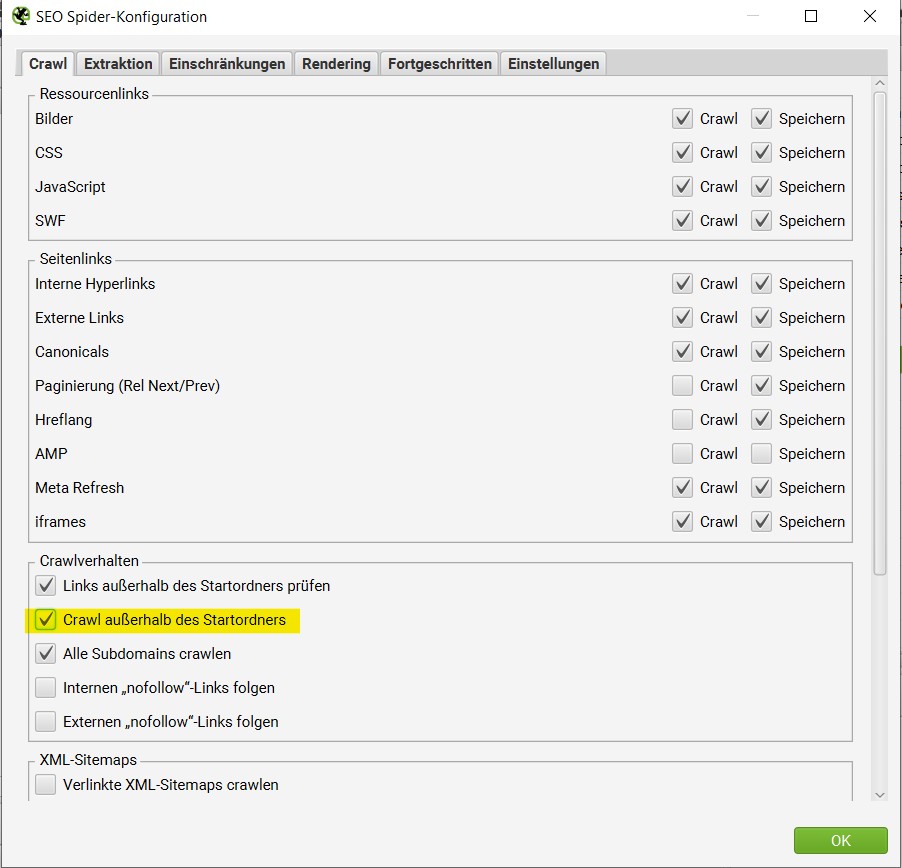
Es gibt außerdem die Möglichkeit, den Spider weitere Seiten analysieren zu lassen, die sich außerhalb des Startordners befinden. So kann der Crawl bei /leistungen starten und trotzdem /blog crawlen und analysieren. Dafür muss im Menüpunkt “Konfiguration“ unter dem Unterpunkt „SEO Spider“ der Punkt „Crawl außerhalb des Startordners“ aktiviert sein.
Zusammenfassung: “Konfiguration“ → „SEO Spider“ → „Crawl außerhalb des Startordners“
Das Ausschließen von Parameter-URLs vor und nach dem Crawl
Mittels “URL-Umschreibung” vor dem Crawl können Einstellungen für das Ausschließen von bestimmten oder allen Parameter URLs getroffen werden. Diese findest Du unter “Konfiguration” → “URL-Umschreibung” → “Parameter entfernen”. Dort kannst Du “Alle entfernen” anklicken und dann den Crawl starten. Wenn Du nur bestimmte Parameter-URLs ausschließen möchtest, dann kannst Du den entscheidenden Begriff eingeben und den Crawl starten.
Wenn Du einfach nur nach dem Crawl alle oder verschiedene URL Parameter ausschließen möchtest, funktioniert dies super mit der Screaming Frog Filterfunktion.
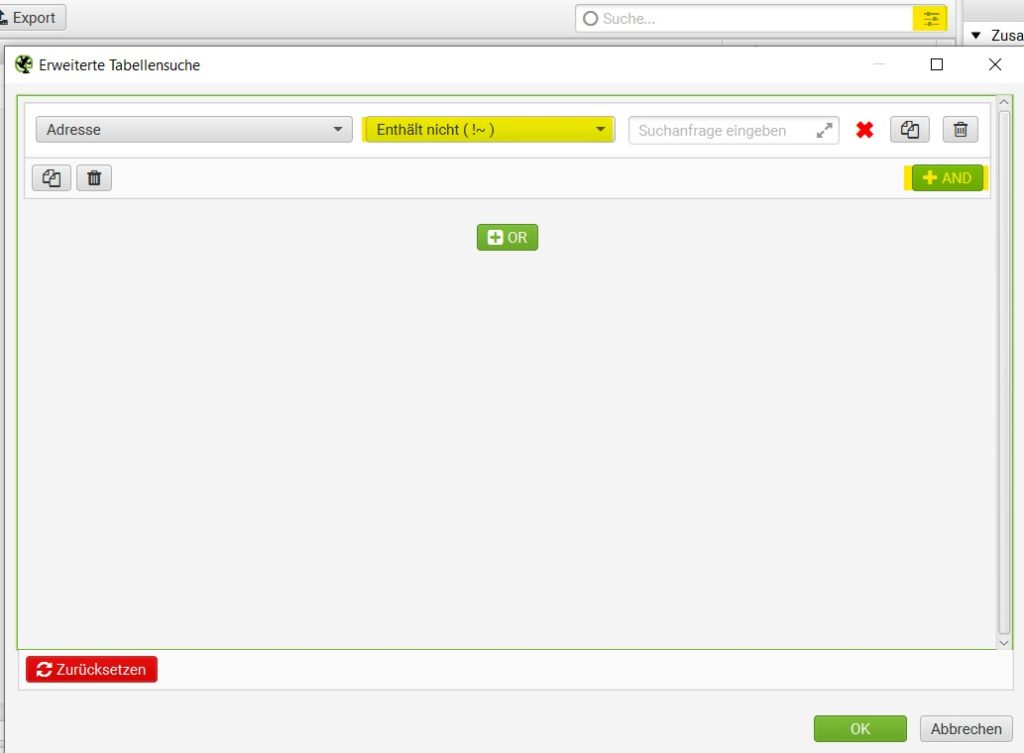
Das Eingrenzen von URL-Gruppen
Welche Einstellungen Du vornehmen musst, wenn Du bestimmte URLs einbeziehen möchtest und wie Du die Unterseiten eines bestimmten spezifischen Unterverzeichnisses crawlst, zeigen wir Dir hier:
Das Crawlen eines speziellen Unterverzeichnisses
Wenn das Crawlen auf ein bestimmtes Unterverzeichnis begrenzt werden soll, reicht es, nur die URL anzugeben, welche durchsucht werden soll und die Suche zu starten.
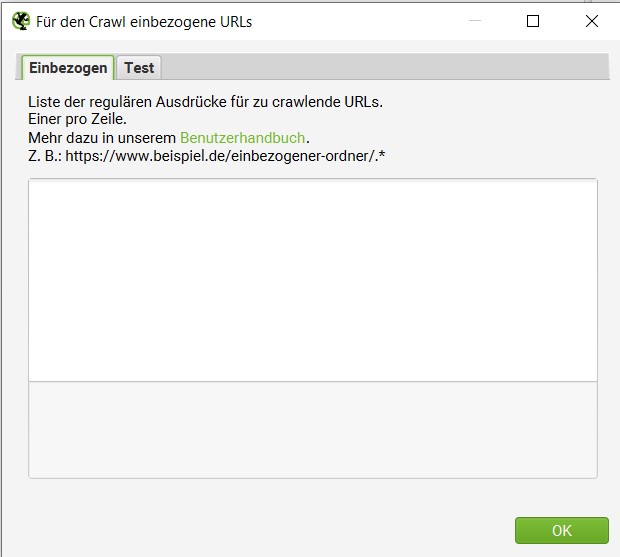
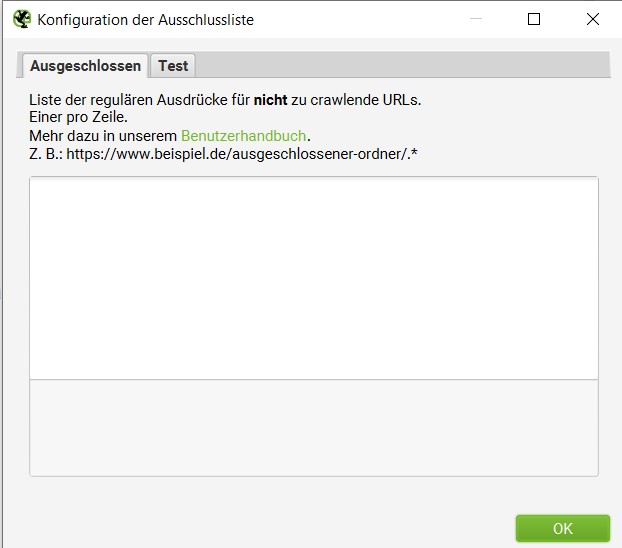
Bestimmte URLs beim Crawl einbeziehen und ausschließen
Soll das Crawlen auf eine bestimmte Auswahl/Liste von Subdomains oder Unterverzeichnissen beschränkt sein, können URLs beim Crawl einbezogen oder ausgeschlossen werden. Dabei können reguläre Ausdrücke für zu/nicht crawlende URLs hinzugefügt werden. Dafür müssen in der “Konfiguration” unter “Einbeziehen” oder “Ausschließen”, die betroffenen URLs hinzugefügt werden.
Zusammenfassung Einbeziehen: Konfiguration → Einbeziehen
Zusammenfassung Ausschließen: Konfiguration → Ausschließen
Auflisten aller Unterseiten einer Internetseite oder eines Verzeichnisses
Auch hier müssen alle Checkboxen unter “Konfiguration” – “SEO Spider” abgewählt werden, damit nur HTML-Dateien gecrawlt werden. Um jetzt die Unterseiten eines bestimmten spezifischen Unterverzeichnisses zu crawlen und die anderen Verzeichnisse zu ignorieren, muss die Checkbox “Crawl außerhalb des Startordners” abgewählt werden. Jetzt liefert Screaming Frog als Ergebnis der Suche eine Liste aller Unterseiten von dem Startordner bzw. dem Startverzeichnis.
Die Unterseiten der Unterseiten werden anhand der internen Verlinkung gefunden und aufgelistet. Somit kann auf diese Weise geprüft werden, ob alle internen Links gesetzt sind oder ob wichtige URLs in der Liste fehlen und noch verlinkt werden müssen.
Zusammenfassung: Konfiguration → SEO Spider → “Bilder“, „CSS“, JavaScript“ und “SWF“ abwählen
Nur für ein gewähltes Unterverzeichnis: Konfiguration → SEO Spider → “Bilder“, „CSS“, JavaScript“ und “SWF“ abwählen
Das Speichern von Konfigurationen
Wenn Einstellungen für weitere Crawls übernommen werden sollen, können die getätigten Einstellungen gespeichert werden. Dafür muss im Menüpunkt Datei“ unter „Konfiguration“ der Punkt „Speichern unter“ ausgewählt werden. Damit wird die Konfiguration auf dem Rechner gespeichert und kann für gewollte Crawls übernommen werden. Sollen die Einstellungen für alle zukünftigen Crawls übernommen werden, kann “Aktuelle Konfiguration als Standard speichern” ausgewählt werden.
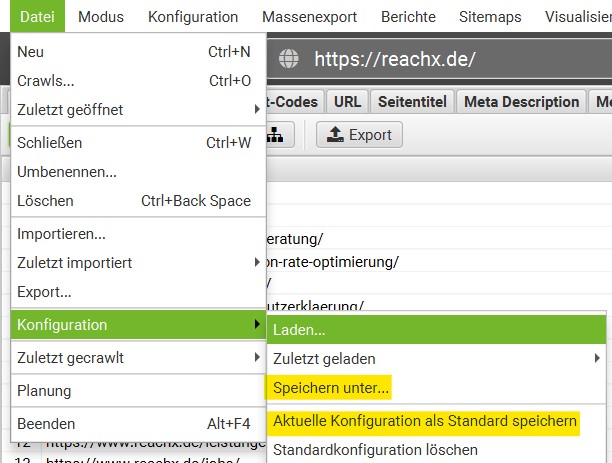
Standardeinstellungen werden wieder gelöscht. Im Menü “Datei“ können durch die Auswahl der Unterpunkte „Konfiguration“ und „Standardkonfiguration löschen“ die Standardeinstellungen wiederhergestellt werden.
Zusammenfassung: Datei → Konfiguration → Standardkonfiguration löschen
Den Inhalt von Webseite prüfen
Für das OnPage SEO ist es wichtig, den Inhalt einer Seite weitestgehend zu optimieren. Generell gilt in 2023, Inhalte zu optimieren, anstatt neue zu erstellen, um Nutzer:innen den optimalen Mehrwert zu bieten. Zur Optimierung in diesem Bereich gehört zum einen einzigartiger und zum anderen aktueller und inhaltlich korrekter Content, welcher für Nutzer:innen und nicht für die Suchmaschine geschrieben wird.
Wortzahl, Rechtschreibung und Grammatik crawlen
Wenn Du nur die Wortzahl Deiner URLs crawlen möchtest, kannst Du diese unter dem Reiter “Inhalt” einsehen.
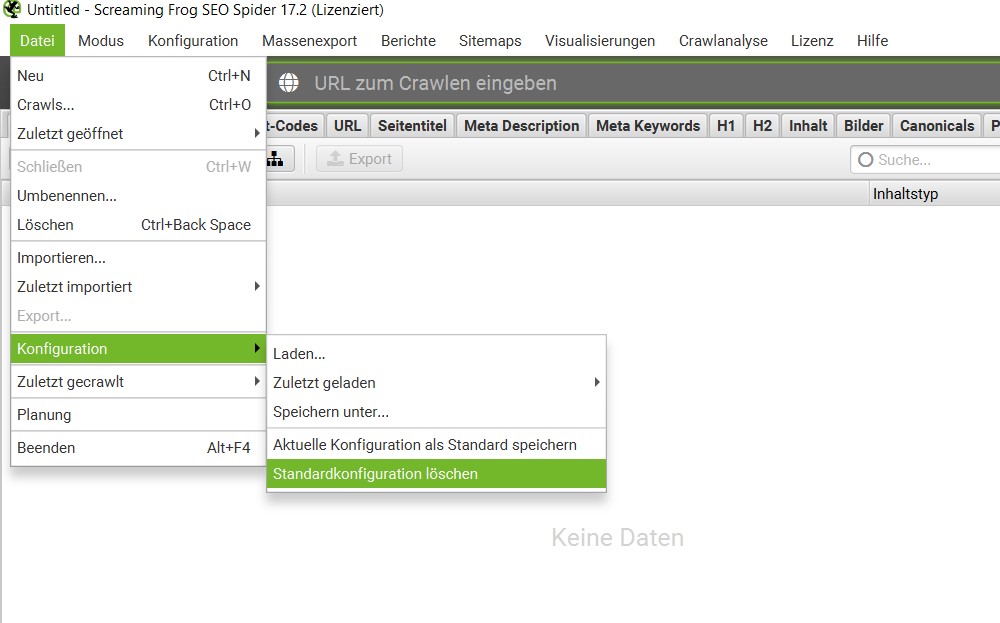
Um die Rechtschreibung und Grammatik im Screaming Frog zu crawlen, müssen Voreinstellungen gemacht werden. Diese findest Du unter “Konfiguration” und “Inhalt”. Unter “Rechtschreibung und Grammatik” kannst Du angeben, dass diese mit gecrawlt werden soll.
Zusammenfassung: Konfiguration → Inhalt → Rechtschreibung und Grammatik
Doppelte Inhalte identifizieren
Unter doppelte Inhalte fallen zum einen doppelte H1’en, Meta-Titels und -Deskription etc., welche immer mit gecrawlt werden. Finden kannst Du diese immer unter dem entsprechenden Reiter “Duplikate”.
Zusammenfassung: Crawling → zum entsprechenden Tab wechseln (Seitentitel, Meta Description, H1) → Filter: “Duplikate“
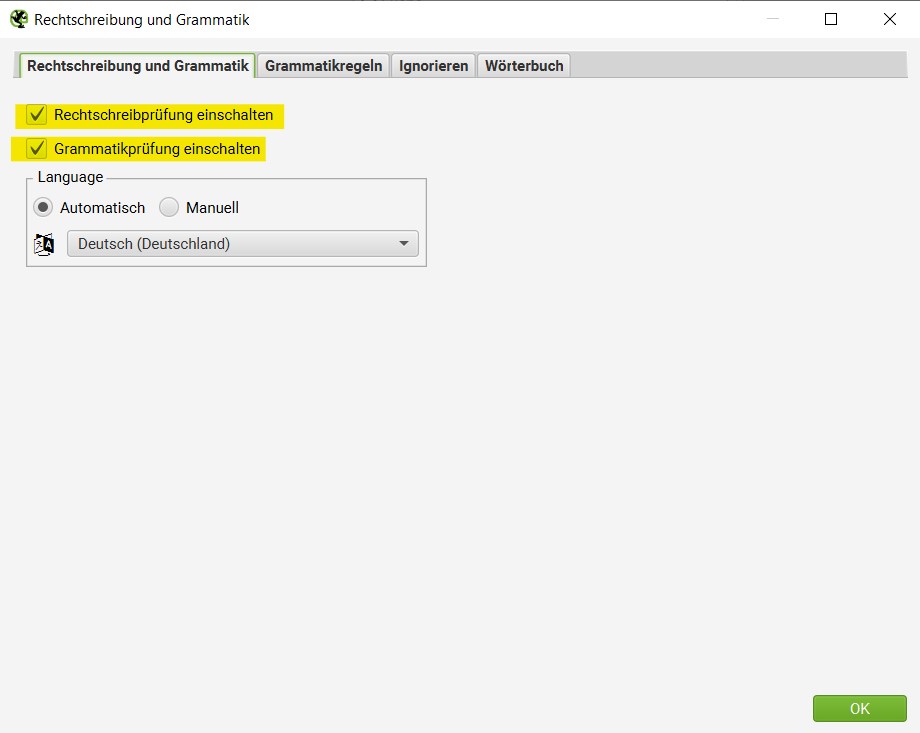
Zum anderen gehören dazu die textlichen Inhalte auf den einzelnen URLs. Um diese “Nahdublikate” zu crawlen, müssen Voreinstellungen getroffen werden. Diese findest Du unter “Konfiguration” dort unter “Inhalt” und “Duplikate”
Zusammenfassung: Konfiguration → Inhalt → Duplikate
Bilder sowie die dazugehörigen Alt-Texte crawlen
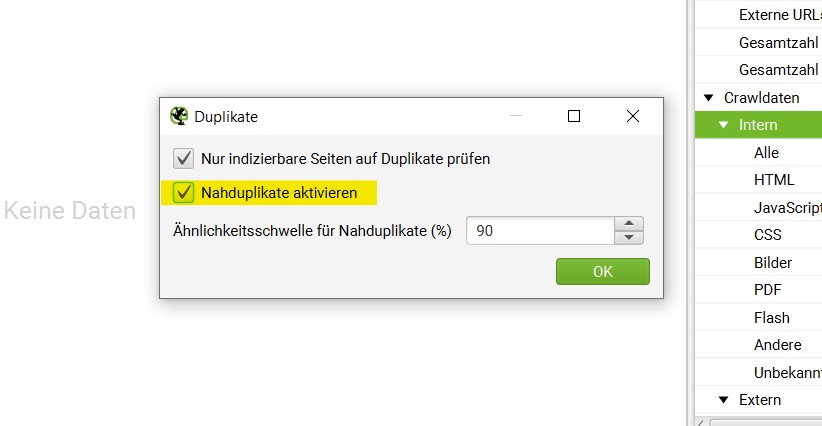
Um alle Bilder mit dem Screaming Frog zu crawlen ist es wichtig, dass im Menü “Konfiguration”→ “SEO Spider“ der Punkt “Bilder“ aktiviert ist. Ansonsten werden Bilder bei der Suche ausgelassen. Ist der Spider mit der Arbeit fertig, kann nun der “Bilder“-Tab ausgewählt werden. Hier besteht die Möglichkeit, 3 verschiedene Filter einzustellen: “Über 100 KB”, “fehlender Alt-Text” und “Alt-Text über 100 Zeichen”.
Wo sich die entsprechenden Bilder befinden, kann durch einen Klick auf „Bilddetails“, am unteren Rand des Bildschirms, herausgefunden werden.
Zusammenfassung: Crawling → “Bilder“-Tab → Filter einstellen → “Bilddetails”
Auflisten von Links zu den Bildern auf einer bestimmten Seite
Um nach dem Crawl die Bilder einer bestimmten URL aufzulisten, wird nach dem Crawlen wieder der “Intern“ Tab ausgewählt und nach HTML gefiltert. Die gewünschte URL wird nun im oberen Fenster ausgewählt. Ganz unten (unter dem zweiten Fenster) besteht jetzt die Möglichkeit, den Punkt „Bilddetails“ auszuwählen. Im unteren Fenster werden alle Bilder einer bestimmten URL mit ihrem Alt-Text angezeigt.
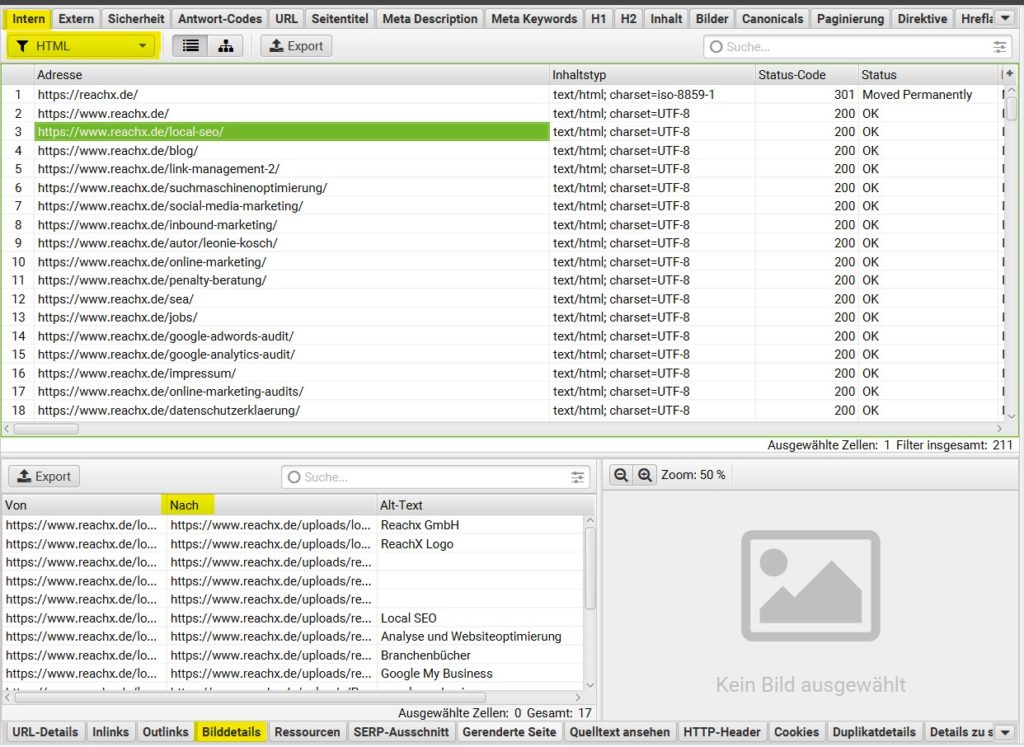
Zusammenfassung: Crawling → Intern → URL anklicken → Bilddetails
CSS- und JavaScript-Dateien finden
Um eine Auflistung aller CSS-Dateien zu erhalten, muss im Menü „Konfiguration → “SEO Spider“ der Punkt “CSS“ ausgewählt sein. Nach der Suche kann über den Reiter „Intern” das Ergebnis nach CSS gefiltert werden.
Zusammenfassung: Crawling → Intern → Dropdown: CSS
Sich alle JavaScript Dateien anzeigen zu lassen, geht mit Screaming Frog ebenfalls sehr einfach. Wichtig hierfür ist das Aktivieren des Punktes “JavaScript“ im Menü unter “Konfiguration” → “SEO Spider“. Nach dem Crawlen können die Ergebnisse im Reiter „Intern” eingesehen werden. An dieser Stelle werden die Ergebnisse über den Filter nach JavaScript Dateien sortiert.
Zusammenfassung: Crawling → Intern → Dropdown: JavaScript
Identifizieren aller jQuery-Plugins und auf welchen Unterseiten sie benutzt werden
Auch für diesen Fall ist es wichtig, dass unter “Konfiguration” die Box “JavaScript“ ausgewählt ist. Dies lässt sich unter „Konfiguration” → “SEO Spider“ einstellen. Die Ergebnisse werden im Reiter „Intern” angezeigt. Um nun alle JavaScript-Dateien anzuzeigen, wird hier der Filter auf “JavaScript” gesetzt. Jetzt ist es möglich, mit der Suche, welche sich über dem oberen Fenster befindet, nach „jQuery“ zu suchen. Als Ergebnis wird eine Liste mit Plugins angezeigt. Anschließend können über den „Inlinks“-Tab unter dem zweiten Fenster die Adressen angezeigt werden, wo die Plugins verwendet werden.
Zusammenfassung: Crawling → Tab: Intern → Filter: JavaScript → Suche: jQuery → Tab: Inlinks

Herausfinden an welcher Stelle der Webseite „Flash“ eingebettet ist
Damit auch Flash bei der Suche berücksichtigt wird, ist es wichtig im Menü “Konfiguration” → “SEO Spider“ den Unterpunkt “SWF“ zu aktivieren. Nach der Suche kann über den „Intern“-Tab mit dem Filter nach Flash sortiert werden. Screaming Frog kann an dieser Stelle nur Dateien mit der Endung .swf finden, die auf der Seite verlinkt sind. Wird das Flash über JavaScript eingebunden, muss ein definierter Filter angelegt werden.
Zusammenfassung: Crawling → Tab: Intern → Filter: Flash
Finden von internen PDF-Dateien, die auf der Webseite verlinkt sind
Ebenfalls können verlinkte PDF-Dateien auf einer Webseite mithilfe der Suche gefunden werden. Um diese anzuzeigen, muss die Suche des Spiders abgeschlossen sein. Danach lässt sich über den Reiter „Intern“ das Ergebnis nach PDF filtern.
Zusammenfassung: Crawling → „Intern“-Tab → Filter: PDF
Social Media Buttons, iFrames und Audio- oder Videocontent finden
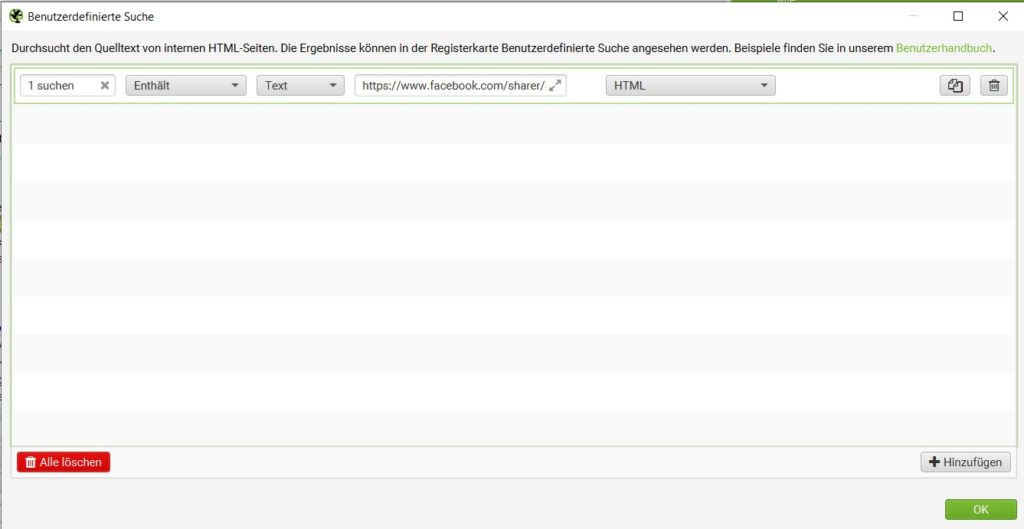
Um Seiten zu finden, auf denen Social Media Buttons eingebunden sind, ist das Erstellen eines definierten Filters nötig. Dieser muss eingestellt werden, bevor die Suche gestartet wird. Dieser Filter kann über das Menü “Konfiguration”→ “Benutzerdefiniert → “Suche“ erstellt werden. Im Filter muss ein Codeauszug der Button-Quellseite, des iFrames oder des eingebetteten Codes für YouTube angegeben werden.
Beispiel: Für jeden Social Media Button muss an dieser Stelle ein Filter verwendet werden. Für den Facebook-Share-Button wäre beispielsweise folgende URL: https://www.facebook.com/sharer/sharer.php
Zusammenfassung: Konfiguration → Benutzerdefiniert → Suche
Die richtige URL-Benennung prüfen
Ist das Crawlen des Spiders abgeschlossen, muss der „URL“-Tab geöffnet werden. An dieser Stelle kann nach “Nicht ASCII-Zeichen“, “Unterstriche“ und “Großbuchstaben“ gefiltert werden. Diese Filter zeigen alle URLs mit einem Unterstrich oder Großbuchstaben an und es werden diejenigen aufgelistet, die auch aus nicht ASCII-Zeichen bestehen.
Zusammenfassung: Crawling → „URL“-Tab → entsprechenden Filter anwenden (“Nicht ASCII-Zeichen“, “Unterstriche“ und “Großbuchstaben“)
Scraping – “Benutzerdefinierte Extraktion” von internen HTML-Seiten mittels “X-Path”
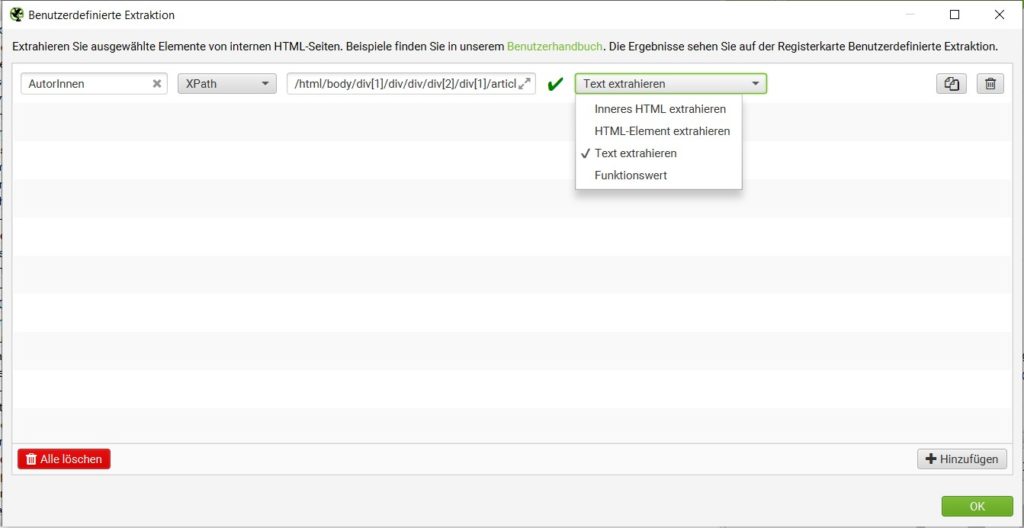
Beim Scraping geht es um das Sammeln von Informationen einer Internetseite mittels individueller Kriterien. Diese können anschließend aufbereitet und/oder weiterverwendet werden. Dabei geht es um das Scraping von eigenen Inhalten und fremden Inhalten. Eigene Inhalte zu analysieren, hilft Dir vor allem beim Optimieren dieser Inhalte. Wie zum Beispiel zum Optimieren von Meta-Daten oder Gruppieren von Inhalten mit gleichen Inhaltskriterien. Bei fremden Websites kannst Du zum Beispiel Preise von Produkten scrapen, um diese bei z.B. einem Preisvergleich einzufügen.
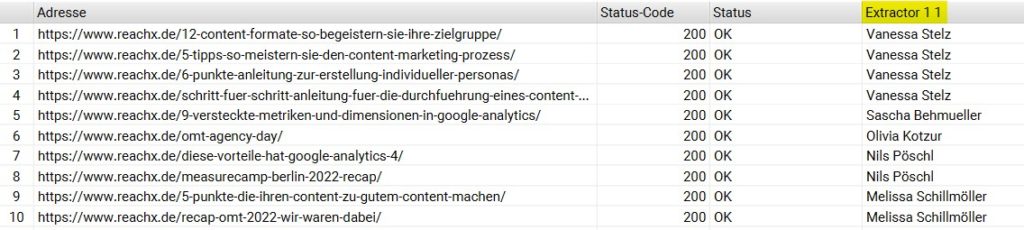
Dafür kannst Du die benutzerdefinierte Extraktion via X-Path bei Screaming Frog nutzen. Als Beispiel habe ich dies an unseren Blog-Artikel aufgezeigt. Dort habe ich mittels X-Path die Autor:innen unserer Blog-Artikel gezogen. Dafür kannst Du Dir im Quelltext der URL den X-Path ziehen und unter “Konfiguration”, “Benutzerdefiniert” und “Extraktion” angeben. Wenn Du nur den Text, wie in meinem Fall, Autor:innen-Namen ziehen möchtest, musst Du “Text extrahieren” im Drop-Down auswählen.
So sehen die gezogenen Daten im Screaming Frog aus. Unter dem Reiter “Benutzerdefinierte Extraktion” kannst Du die gezogenen Daten anschauen.
Die Links auf Deiner Domain analysieren
Durch gewisse OnPage Link-Maßnahmen ist es möglich, Nutzer:innen den Aufenthalt auf einer Seite angenehmer zu gestalten, hilfreiche weiterführende Inhalte bereitzustellen und den gesamten Aufenthalt zu verlängern.
Den Status-Code Deiner URLs überprüfen
Um den Status Code von Deinen Links zu kontrollieren, lässt Du zunächst einen Crawl laufen. Die Antwort Codes findest Du dann unter dem Reiter “Antwort-Codes”. Wichtig ist es, dass Deine Domain keine 404- und 500-URLs besitzt. Am besten haben alle URLs einen 200 Status.
Zusammenfassung: Crawling → „Intern“-Tab → nach Status Code sortieren → Massenexport (Massenexport → Links → Alle-In-links)
Finden aller weitergeleiteten Links
Es gibt 2 verschiedene Gründe, weitergeleitete Links crawlen zu wollen.
Du benötigst eine Weiterleitungs-Liste von allen URLs, die weitergeleitet wurden, um herauszufinden, ob Du auf eine 404 Seite verlinkst. Oder Du willst checken, ob Du interne Verlinkungen auf 301 Weiterleitungen besitzt.
- Wenn Du eine Liste von allen weitergeleiteten URLs haben möchtest, musst Du den Crawl über die Listenfunktion starten. Damit checkt der Crawler alle URLs einzeln und kann Dir somit das Umleitungsziel der URLs ausspielen.

- Um die interne Verlinkung von 3xx URLs zu checken, startest Du wie gewohnt einen Crawl. Unter dem Reiter “Antwort-Codes” mit dem Filter “Umleitung (3xx)” erhältst Du die gewünschte Liste. Alle diese URLs solltest Du checken und die Verlinkungen zur gewünschten 200-URL umändern. Damit minimierst Du Ladezeiten und Weiterleitungsketten. Wichtig zu beachten ist hier, dass der SF nicht Deine weitergeleiteten URLs crawlt, sondern verlinkte Links auf Deinen URLs, welche weitergeleitete URLs sind. Dies kann den PageSpeed und das Erlebnis für Nutzer:innen verschlechtern, da beim Klick auf eine Verlinkung nicht die gewünschte URL geöffnet wird, sondern die URL, auf die weitergeleitet wurde.
Interne und externe Links einer Webseite auflisten
Wenn Informationen über interne und externe Links angezeigt werden sollen, kann dafür der “Massenexport” für bestimmte Informationen verwendet werden. Es können z. B. alle Inlinks, alle Outlinks, External Links und alle Ankertexte exportiert werden. Als Ergebnis erhältst Du verschiedene Listen mit den zugehörigen Linklocations.
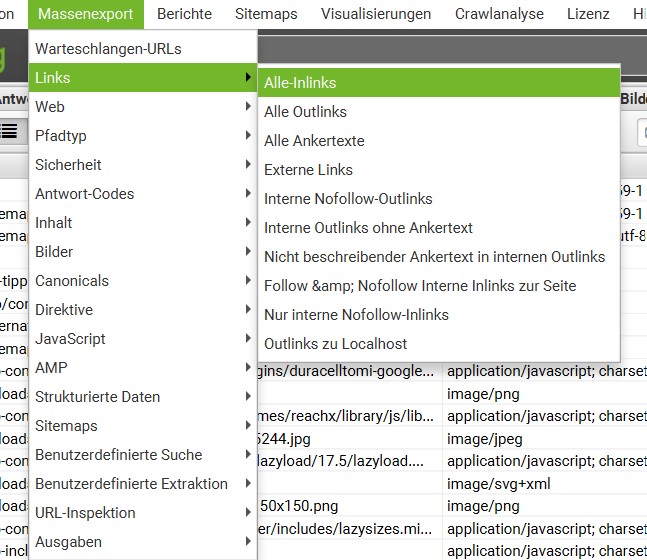
Auffinden aller ausgehenden Links
Es ist nicht nur wichtig, dass die eigenen URLs auf dem Status 200 laufen, sondern auch die ausgehenden Verlinkungen auf andere Domains. Wenn Du User:innen auf 404- (oder HTTP-)URLs schickst, kann dies dazu führen, dass User:innen nicht mehr auf Deine Seite zurückkehren. Ist die Suche der Spinne abgeschlossen, muss zum „Extern“-Tab gewechselt werden. Hier werden im oberen Fenster alle URLs angezeigt, die im durchsuchten Bereich verlinkt sind. Die Liste der URLs kann nun nach Statuscode sortiert werden. So können externe URLs mit einem invaliden Statuscode schnell und einfach gefunden werden.
Wird nun eine einzelne URL ausgewählt, wird durch das Wechseln auf den Tab „Inlinks“, im unteren Bereich des Fensters, eine Liste mit den Seiten angezeigt, die auf diese externe URL verlinken.
Zusammenfassung: Crawling → „Extern“-Tab → nach Status Code sortieren → im unteren Bereich nach “Inlinks” sortieren

EXTRA Tipp: Mögliche Backlinkquellen finden
Wenn Du kein eigenes Tool für die Analyse von Backlinks hast, kannst Du Domains crawlen, die von Deinen Inhalten profitieren würden. Wenn diese Domain auf URLs verlinken, die auf einer 404-Seite landen, kannst Du Dein Glück probieren und eine passende Seite von Dir zum Verlinken bei der Firma vorschlagen.
So analysiert Du Inhalte Deiner SERPs
Bei der SERP-Analyse mit dem Screaming Frog können Metadaten und strukturierte Daten analysiert sowie Meta-Direktiven entdeckt werden.
Identifizieren von fehlenden, zu langen & kurzen und doppelten Seitennamen & Meta-Beschreibungen
Die Daten können in den jeweiligen Reitern “Seitentitel” und “Meta Description”gefunden werden. Mit dem Filter “Fehlende”, “Über 155 Zeichen”, “Unter 70 Zeichen” sowie “Duplikate” können diese angezeigt werden.
Zusammenfassung Seitentitel: Crawling → „Seitentitel“-Tab → Filter
Zusammenfassung Meta-Description: Crawling → „Meta Description“-Tab → Filter
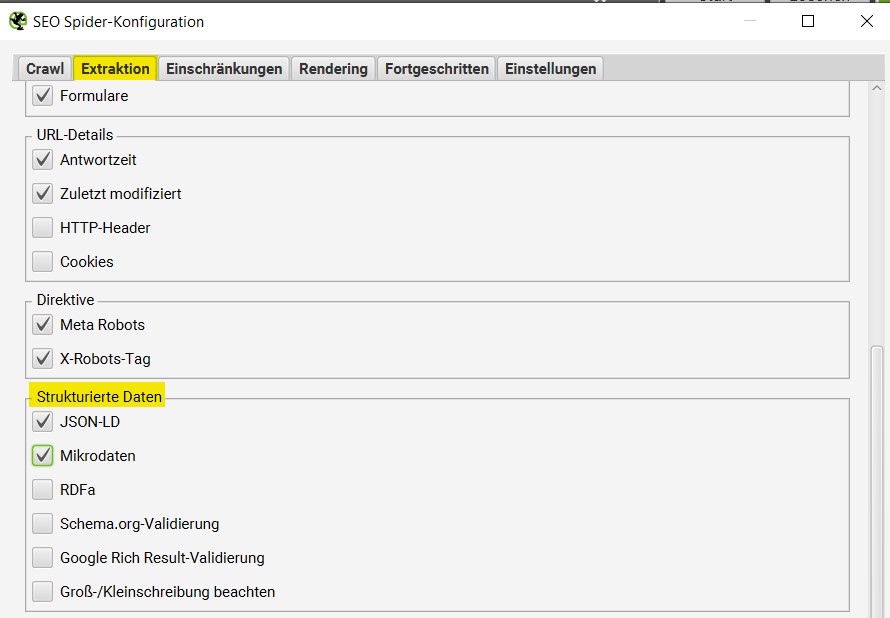
Strukturierte Daten identifizieren
Um jede Unterseite zu finden, welche Schema-Markup oder eine andere Form von Mikrodaten enthält, musst Du Konfigurationen dafür vornehmen. Unter “SEO Spider” findest Du diese über “Extraktion”. Dort kannst Du die gewünschten Harken setzen und den Crawl starten.
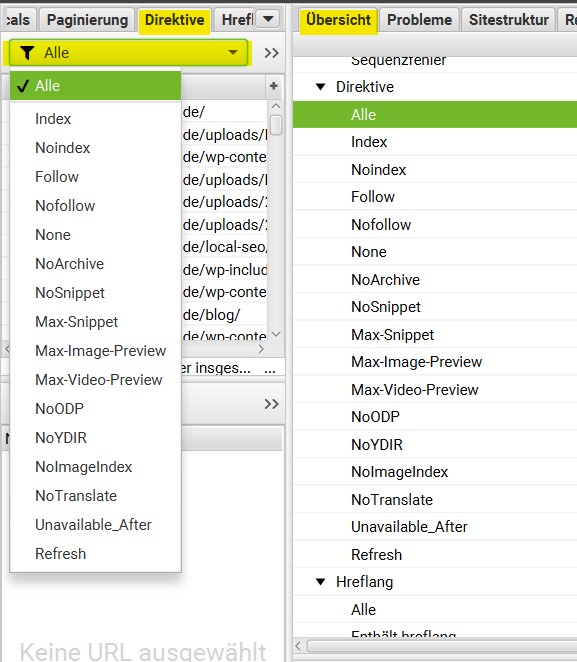
Metadirektiven identifizieren
Um Informationen über das (nicht) Ausspielen von Daten in den Suchergebnissen zu finden, kann der “Direktive” Tab hilfreich sein. Nach dem Crawl können alle relevanten Informationen im „Direktive“-Tab gefunden werden. Um herauszufinden, um welche Direktive es sich handelt, sollten die einzelnen Spalten betrachtet werden. Alternativ können auf diese Liste auch Filter angewendet werden. Dort werden z. B. die Direktiven “Index”, Noindex, “Follow”, “Nofollow”, “NoSnippet”, “Max-Image-Preview” etc. angezeigt.
Wie Du eine Sitemap crawlen und erstellen kannst
Mit einer Sitemap werden alle URLs der dazugehörigen Internetseite in einer bestimmten Form aufgestellt. Diese Form ist lesbar für Maschinen und wird in der Google Search Console hinterlegt. Dadurch steigt die Wahrscheinlichkeit stark an, dass diese dort abgelegten URLs bei einer Suche gecrawlt werden.
Überprüfen einer existieren XML-Sitemap
Eine aufgeräumte und aktuelle Sitemap ist für die OnPage Optimierung wichtig. Denn damit zeigst Du Google, welche Inhalte besonders wichtig für Dich sind. Die Chance, dass Deine Inhalte gecrawlt werden, erhöht sich zudem auch.
Um eine bereits existierende Sitemap zu überprüfen, wird entweder eine Kopie der XML-Datei auf dem eigenen Computer benötigt oder sie muss aus der Sitemap rauskopiert werden. Der Link zur Sitemap ist in der robots.txt zu finden. Außerdem kann die Sitemap in der Google Search Console angezeigt werden. Die URLs sind dort unter “Indexierung” – “Seiten” – “/sitemap.xml” zu finden.
Im Screaming Frog über “Modus” – “Liste” kannst Du die Sitemap crawlen. Nach Beendigung der Suche lassen sich Fehler, Weiterleitungen, doppelte URLs und andere Dinge, die es in der Sitemap zu bereinigen gilt, im Tab „Intern“ anzeigen.
Zusammenfassung: Kopie der Sitemap via Listenmodus einfügen → Crawlen → „Intern“-Tab
Mit dem Screaming Frog eine XML-Sitemap erstellen
Um eine neue XML-Sitemap zu erstellen, muss die betreffende Webseite erst gecrawlt werden. Die Map lädst Du unter “Sitemaps” – “XML-Sitemap” über “Export” runter. Dort kannst Du alle nötigen Einstellungen treffen. Inhalte, die nicht gecrawlt werden sollen, sollten nicht in der Sitemap vorhanden sein und zudem in der robots.txt blockiert werden. Dort kannst Du bestimmte Seiten und Verzeichnisse angeben. Ist alles korrekt, kannst Du die Sitemap in der Google Search Console einreichen.
Zusammenfassung: Crawling → Sitemaps → XML-Sitemap → Export
So erweiterst Du Deine Themen-/Keyword-Recherche
Neben den “traditionellen” Keyword– und Wettbewerbsrecherchen mit ahrefs, sistrix oder Google Ads gibt Dir der Screaming Frog die Möglichkeit wichtige Seiten Deiner Wettbewerber:innen und eine Ankertext-Analyse vorzunehmen.

Wichtige URLs bei Wettbewerber:innen feststellen
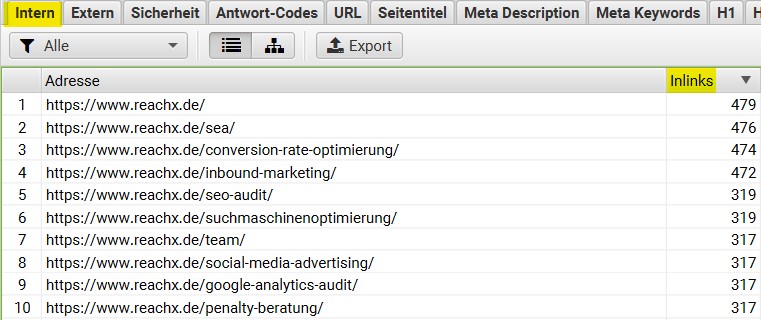
Mit Onpage Link-Maßnahmen für eine Hauptseite bzw. wichtige URL, kann diese gestärkt werden. Zum Beispiel mit dem Verlinken von internen Inhalten zum Stärken dieser Inhalte. Bei welchen Inhalten dies bei Wettbewerber:innen der Fall ist, lässt sich leicht überprüfen. Möglicherweise sind Hauptseiten vorhanden, die auch für Dich relevant sind.
Unter dem Reiter “Intern” findest Du die Anzahl der internen Links auf den gecrawlten URLs. Bei vielen Inlinks, kannst Du davon ausgehen, dass die URL relevant für Deine Wettbewerber:innen sind.
Ankertexte für interne Verlinkungen analysieren
Um herauszufinden, welche Ankertexte Wettbewerber:innen für ihre Verlinkungen nutzen, kann die Exportfunktion in Screaming Frog genutzt werden. Nach dem Crawlen der betreffenden Internetseite kann per „Massenexport” → “Links” → Alle Ankertexte“ eine CSV-Datei mit allen Ankertexten exportiert werden.
Die Einbindung von Tools
Der SF bietet einige Api Schnittstellen an.

Google Analytics bietet einen Nutzen für das Marketing als auch für Webmaster und SEO: für die OnPage Optimierung, die Analyse von “Besucherquellen”, den Traffic, das A/B-Testing und auch über den Erfolg von Werbung und Marketing.
Auch weitere Tools, wie die Search Console und der PageSpeed Insight können verbunden werden. Diese müssen vor dem Crawling über das Einstellungssymbol neben dem gewünschten Tool verbunden werden.
Fazit
Der Screaming Frog ist ein geniales Tool, um die eigene, aber auch alle anderen Seiten im Netz zu untersuchen. So können Schwachstellen an eigenen Projekten, aber auch Ansätze von konkurrierenden Seiten aufgedeckt werden, um sein eigenes Ranking und die gesamte Website Health zu steigern.
Sollten sich Fragen zum Screaming Frog ergeben, stehe ich Dir gerne mit Rat und Tat zur Seite. Wir verwenden innerhalb unseres SEO-Audit den Screaming Frog, um unseren Kund:innen eine optimale technische Analyse darlegen zu können – und das mit Erfolg!
Jetzt Unterstützung in SEO erhalten
